The Phi model family represents Microsoft's focused effort to develop efficient and capable small language models (SLMs) with particular emphasis on mathematical and scientific reasoning capabilities. The family culminates in Phi-4, released in December 2024, which demonstrates significant advances in model architecture and training methodology while maintaining a relatively compact parameter count compared to other leading language models.
Overview
The Phi series represents Microsoft's strategic approach to developing language models that prioritize efficiency and specialized capabilities over sheer size. Phi-4 builds upon its predecessor Phi-3-medium, showcasing Microsoft's iterative improvement in model development. The family is particularly notable for its focus on STEM-related tasks and complex reasoning capabilities, achieved through sophisticated training techniques and carefully curated datasets.
Technical Architecture
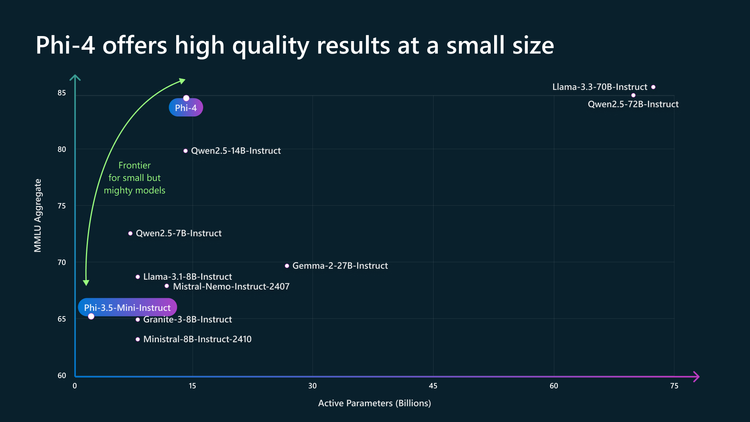
The Phi family's latest iteration, Phi-4, employs a dense decoder-only Transformer architecture with 14 billion parameters. A significant architectural feature across the family is the use of the tiktoken tokenizer, which provides enhanced multilingual support. The models are designed with scalability in mind, as evidenced by Phi-4's ability to handle a 16K token context length, which was upgraded from 4K during its training process, as detailed in the technical report.
Training Methodology
The training methodology of the Phi family has evolved significantly, with Phi-4 representing the most advanced approach. The training process involved an impressive scale of computation, utilizing 1920 H100-80G GPUs over a 21-day period to process approximately 9.8 trillion tokens. The training data composition reflects a careful balance between different sources, including synthetic data (40%), web data (15%), web rewrites (15%), code data (20%), and acquired sources (10%).
A distinctive aspect of the family's evolution is the shift from primarily distilling capabilities from GPT-4 to incorporating more sophisticated training techniques. This includes multi-agent prompting, self-revision workflows, and instruction reversal. The synthetic data generation process was particularly extensive, producing approximately 400 billion unweighted tokens across 50 different types of synthetic datasets.
Performance and Capabilities
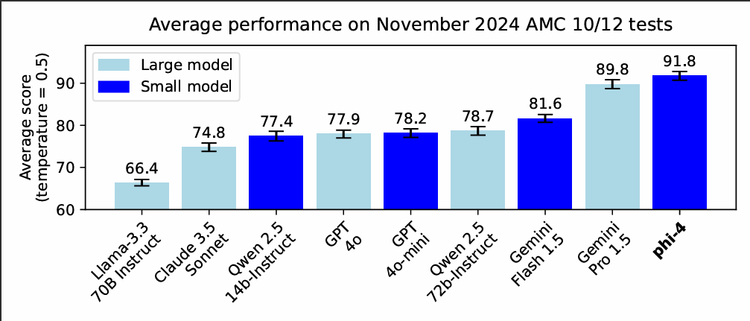
The Phi family demonstrates particularly strong performance in STEM-related tasks, with Phi-4 showing exceptional capabilities in mathematical reasoning. When compared to similar-sized models, such as Qwen-2.5-14B-Instruct, Phi-4 shows superior performance across multiple benchmarks. Notably, it outperforms GPT-4o on specific benchmarks like GPQA and MATH, while also achieving leading scores in coding benchmarks among open-weight models.
Safety Features and Implementation
Safety considerations have been a crucial aspect of the Phi family's development. The models incorporate comprehensive post-training safety measures, including multiple rounds of Direct Preference Optimization (DPO) and a novel "Pivotal Token Search" (PTS) method. The safety approach also includes judge-guided optimization using GPT-4o and extensive efforts to mitigate hallucination risks.
Limitations and Constraints
Despite their advanced capabilities, the Phi models have certain limitations that users should be aware of. These include potential output bias, the possibility of generating inappropriate content, and concerns about information reliability. In terms of coding capabilities, the models are primarily effective with Python and common packages, with limitations in other programming languages.
Distribution and Licensing
The Phi family models are released under the MIT license, making them accessible for research and development purposes while promoting responsible AI practices. This approach aligns with Microsoft's commitment to open research and collaborative development in the AI community, as evidenced by the model's availability through the Hugging Face Model Repository.
Legacy and Impact
The Phi family represents a significant contribution to the field of small language models, demonstrating that highly capable AI systems can be developed without necessarily scaling to extremely large parameter counts. The family's focus on mathematical and scientific reasoning, combined with its efficient architecture and sophisticated training methodology, has established new benchmarks for what can be achieved with moderate-sized language models.
Future Developments
While specific plans for future models in the Phi family are not detailed in the available information, the success and capabilities of Phi-4 suggest potential for continued development and improvement in areas such as context length, multilingual support, and specialized task performance. The family's emphasis on efficiency and focused capability development may influence future trends in language model development across the industry.

